
Introduction
The AI defense attorney was unaware of a recent case proceeding that the prosecution had just submitted in court. He looked through its internal database, but he couldn’t discover the solution. At this point, the courtroom is silent.
“Objection!” When his assistant, “RAG,” abruptly spoke out, he and an AI defense attorney presented a recent Supreme Court decision that completely altered the case.
When the AI lawyer returned from the courtroom after winning, he asked RAG. “Where did you discover that?” RAG answered with a smile. I extract that information from the most recent case files found in the legal databases. So, now you need not be worried anymore.
What is RAG?
Consider AI Defense Lawyer as LLMs (Large Language Models) like ChatGPT or DeepSeek, which return results based on the data they are trained on. Updating these models is not an easy task and cannot be done daily, as they require a lot of computing power. So if you ask for any latest updates (in our case, any new proceedings, rules, or orders), LLM might not be able to answer it correctly. This is known as hallucination (we will see it in a bit).
Here comes the RAG (Retrieved Augmented Generation), which, along with the user query, gives the context to LLM, using which LLM can respond correctly. Like in our case, the RAG assistant fetched the latest legal documents in real time and gave them to the AI Defense Lawyer (LLM).
This means our defense lawyer (LLM) no longer has to worry about the latest updated data all the time; his assistant (RAG) is here to help.
So, the definition of RAG (Retrieval-augmented Generation) from Wikipedia
“is a technique that enables generative artificial intelligence (Gen AI) models to retrieve and incorporate new information.”
Understanding LLM Hallucinations
When the prosecution presented the most recent case in court, the AI defense attorney (LLM) attempted to recall the case using the legal information he had stored in his head (model/data) and attempted to enter a plea. However, the judge just dismissed his plea because it appeared to be genuine but was a fabrication. This is an example of hallucination.
Accordingly, the definition of hallucination in Wikipedia
is a response produced by artificial intelligence that presents inaccurate or misleading information as fact is called a hallucination, or artificial hallucination.
Another instance from real life is when you have a computer assignment to finish but have no knowledge of the subject. Based on your experience, you produce an assignment that appears to be almost accurate but is actually inaccurate and nonexistent.
Before understanding how RAG helps prevent hallucinations, let’s see how it works.
How RAG Works?
There are two parts to RAG working:
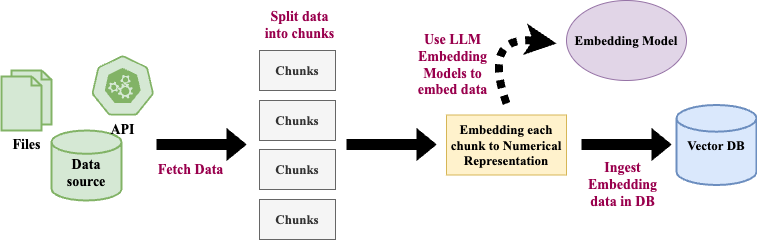
1. Ingestion
Below is the step-by-step process of the RAG ingestion process.
Step 1: The relevant information/data is fetched from the datasources like file repositories, databases, and APIs. In our case the RAG assistant searched for the recent legal files.
Step 2: The data is divided into chunks.
Step 3: Each chunk is embedded using an LLM embedding model and converted into a numerical representation.
Step 4: The numerical representation or embedding is then stored into a vector database.
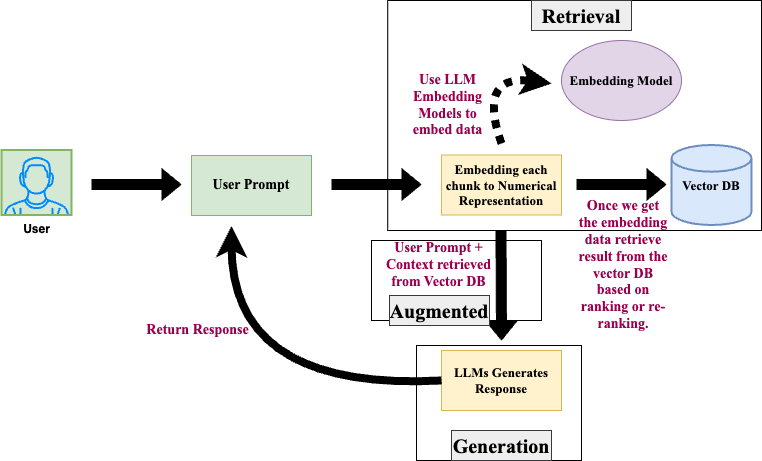
2. Retrieval
Below is the step-by-step process of the RAG retrieval process.
Step 1: The user sends the query to RAG. In our case, the recent case proceeding that the prosecution had just submitted in court.
Step 2: The same LLM model is used for embedding user input.
Step 3: Retrieval Phase: The relevant records are being fetched from the vector DB using the embedding and ranking/re-ranking done in Step 2. These records give relevant context. In our case, the RAG assistant fetched a few legal documents and decisions that can be used as context for the case.
Step 4: Augmented Phase: In this step, RAG submits the user prompt and the context/embeddings it fetched in Step 3 to AI.
Step 5: Generation Phase: In this step, AI generates a response based on its previous knowledge and the context submitted by RAG from Step 4.
How RAG Helps Prevent AI Hallucinations
RAG helps prevent AI hallucination by
- Retrieving Latest Information—RAG provides the latest information from its database to AI to prevent pulling outdated or inappropriate results. In our case, the RAG assistant pulls the latest proceedings and decisions from its database.
- Retrieving Factual/Actual Information—LLMs are powerful enough to generate creative and engaging text, but sometimes they are missing the latest or factual information. RAG provides LLM factual information, which will reduce AI hallucinations.
- Ranking for Reliability—From the data RAG pulls from vector DB, it ranks the data for higher creditability and latest information to ensure AI gets better context and the latest information. In our case, the RAG assistant only provided the latest Supreme Court decision.
With the help of RAG AI, the lawyer no longer hallucinated anything and provided real legal documents.
Variants of RAG
1. Corrective RAG:
Corrective RAG is a strategy that verifies and corrects the embedding searches before sending them to LLMs.
Example: RAG fetched the latest proceeding, and decisions are fetched. RAG then discarded all the incorrect information and only selected the Supreme Court decision.
2. Agenetic RAG:
Agentic RAG is a strategy where RAG improves itself with past learning and interactions. It evolves based on user behavior.
Example: RAG assistant was hearing all the proceedings and getting multiple legal documents for AI Lawyer, and after hearing and interacting, it understood the whole case better and finally fetched the latest Supreme Court decision.
3. Adaptive RAG:
Adaptive RAG is the strategy of adaptation. In this, RAG adapts itself to the changing context of the user query.
Example: In the courtroom when the prosecution changed the context of the case with the recent preceding document of another case. RAG adapts the context and fetches the Supreme Court decision.
For more RAG variants, please refer to the Types of RAG
When to Use (or Avoid) RAG
✅ Use RAG When:
RAG is especially helpful in situations where
- Knowledge in real time is necessary.
- Beyond its trained dataset, the model requires additional information.
- Accurate facts are essential.
❌ Avoid RAG When:
Even with its advantages, RAG isn’t always the best option. Don’t use it when:
- The necessary information is constant.
- You lack a retrieval source from which to obtain data.
- RAG’s introduction will cause the system to experience more delays. If you require low latency, you should avoid using RAG.
Conclusion: Solving the Case
We observed that the AI lawyer (LLM) won the case and was able to uncover the missing fact with the assistance of RAG. With the most recent and pertinent data and case studies, AI Lawyer (LLM) is now more potent not just in this instance but also in future ones. Thanks to RAG, his assistant.
Call to Action:
The AI lawyer (LLM) is evolving with RAG and becoming more powerful.
Your product can also be more accurate and powerful with RAG assistance. RAG is assisting in all fields, whether it’s law, healthcare, finance, IT, or research. With integrating with Retrieval Augmented Generation (RAG), AI is not only giving responses—it’s retrieving, verifying, correcting, and enhancing the responses with real-time knowledge.
Go deep in RAB with our other blog posts and take your AI capabilities to the next level! 🚀

Excellent work.